Project Information
KLay Layered is a layer-based layout algorithm mainly intended for diagrams with an inherent data flow direction. This page describes its general architecture, while child pages discuss the different phases, its intermediate processors, and other specialized topics.
Contents
Architecture
To get an idea of how KLay Layered is structured, take a look at the diagram below. The algorithm basically consists of just three components: layout phases, intermediate processors and an interface to the outside world. Let's briefly look at what each component does before delving into the gritty details.
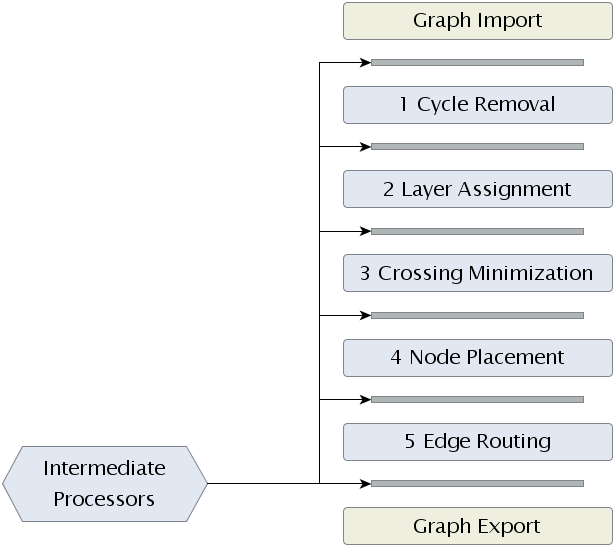
The backbone of KLay Layered are its five layout phases, of which each is performing a specific part of the work necessary to layout a graph. The five phases go back to a paper by someone whose name I'm currently too lazy to look up. They are widely used as the basis for layout algorithms, and can be found in loads of papers on the topic. A detailed description of what each layout phase does can be found below.
Intermediate processors are less prevalent. In fact, it's one of our contributions to the world of layout algorithms. The idea here is that we want KLay Layered to be as generic as possible, supporting different kinds of diagrams, laid out in different kinds of ways. (as long as the layout is based on layers) Thus, we are well motivated to keep the layout phases as simple as possible. To adapt the algorithm to different needs, we then introduced small processors between the main layout phases. (the space between two layout phases is called a slot) One processor can appear in different slots, and one slot can be occupied by more than one processor. Processors usually modify the graph to be laid out in ways that allow the main phases to solve problems they wouldn't solve otherwise. That's an abstract enough explanation for it to mean anything and nothing at once, so let's take a look at a short example.
As will be seen below, the task of phase 2 is to produce a layering of the graph. The result is that each node is assigned to a layer in a way that edges always point to a node in a higher layer. However, later phases may require the layering to be proper. (a layering is said to be proper if two nodes being connected by an edge are assigned to neighboring layers) Instead of modifying the layerer to check if a proper layering is needed, we introduced an intermediate processors that turns a layering into a proper layering. Phases that need a proper layering can then just indicate that they want that processor to be placed in one of the slots.
The interface to the outside world finally allows us to plug our algorithm into the programs wanting to use it. While not strictly part of the actual algorithm, that interface allows us to lay out graphs people throw at us regardless of the data structures used to represent those graphs. Internally, KLay Layered uses a data structure called LGraph to represent graphs. (an LGraph can be thought of as a lightweight version of KGraph, with the concept of layers added) All a potential user has to do is write an import and export module to make his graph structure work with KLay Layered. Currently, the only module available is the KGraphImporter, which makes KLay Layered work with KIML.
Dummy Nodes
Before getting down to it, one other thing is worthy of our attention: dummy nodes. Dummy nodes are nodes inserted into the graph during the layout process. They were not in the original graph that is to be laid out, and are removed prior to the layout being applied to the original graph structure. So why then do we need them?
The different layout phases often have very specific requirements concerning the graph's structure. Real-world graphs usually don't meet these requirements. We could of course respond to that by enabling the phases to cope with these kinds of adverse conditions. But it's much simpler to just insert a few dummy nodes to make the graph fit the requirements.
See the graph below for an example. The orange nodes were layered, but the layering was by no means a proper layering. Thus, gray dummy nodes were added.
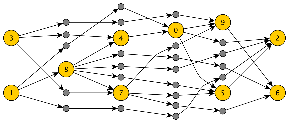
In KLay Layered, we make extensive use of dummy nodes to reduce complex and very specific problems such that we can solve them using our general phases. One example is how we have implemented support for ports on the northern or southern side of a node.
Phases
This page describes the algorithm's five main phases and the available implementations. You can find a list and descriptions of the intermediate processors below.
Phase 1: Cycle Removal
The first phase makes sure that the graph doesn't contain any cycles. In some papers, this phase is an implicated part of the layering. This is due to the supporting function cycle removal has for layering: without cycles, we can find a topological ordering of the graph's nodes, which greatly simplifies layering.
An important part to note is that cycles may not be broken by removing one of their edges. If we did that, the edge would not be routed later, not to speak of other complications that would ensue. Instead, cycles must be broken by reversing one of their edges. Since the problem of finding the minimal set of edges to reverse to make a graph cycle-free is NP-hard, (or NP-complete? I don't remember from the top of my head) cycle removers will implement some heuristic to do their work.
The reversed edges have to be restored at some point. There's a processor for that, called ReversedEdgeRestorer. All implementations of phase one must include a dependency on that processor, to be included after phase 5.
Precondition
- No node is assigned to a layer yet.
Postcondition
- The graph is now cycle-free. Still, no node is assigned to a layer yet.
Remarks
- All implementations of phase one must include a dependency on the ReversedEdgeRestorer, to be included after phase 5.
Current Implementations
- GreedyCycleBreaker. Uses a greedy approach to cycle-breaking.
Phase 2: Layering
The second phase assigns nodes to layers. (also called ranks in some papers) Nodes in the same layer are assigned the same x coordinate. (give or take) The problem to solve here is to assign each node x a layer i such that each successor of x is in a layer j>i. The only exception are self-loops, that may or may not be supported by later phases.
It must be differentiated between a layering and a proper layering. In a layering, the above condition holds. (well, and self-loops are allowed) In a proper layering, each successor of x is required to be assigned to layer i+1. This is possible only for the simplest cases, but may be required by later phases. In that case, later phases use the LongEdgeSplitter processor to turn a layering into a proper layering by inserting dummy nodes as necessary.
Note that nodes can have a property associated with them that constraints the layers they can be placed in.
Precondition
- The graph is cycle-free.
- The nodes have not been layered yet.
Postcondition
- The graph has a layering.
Remarks
- Implementations should usually include a dependency on the LayerConstraintHandler, unless they already adhere to layer constraints themselves.
Current Implementations
- LongestPathLayerer. Layers nodes according to the longest paths between them. Very simple, but doesn't usually give the best results.
- NetworkSimplexLayerer. A way more sophisticated algorithm whose results are usually very good.
Phase 3: Crossing Reduction
The objective of phase 3 is to determine how the nodes in each layer should be ordered. The order determines the number of edge crossings, and thus is a critical step towards readable diagrams. Unfortunately, the problem is NP-hard even for only two layers. Did I just hear you saying "heuristic"? The usual approach is to sweep through the pairs of layers from left to right and back, along the way applying some heuristic to minimize crossings between each pair of layers. The two most prominent and well-studied kinds of heuristics used here are the barycenter method and the median method. We have currently implemented the former.
Our crossing reduction implementations may or may not support the concepts of node successor constraints and layout groups. The former allows a node x to specify a node y!=x that may only appear after x. Layout groups are groups of nodes. Nodes belonging to different layout groups are not to be interleaved.
Precondition
- The graph has a proper layering. (except for self-loops)
- An implementation may allow in-layer connections.
- Usually, all Nodes are required to have at least fixed port sides.
Postcondition
- The order of nodes in each layer is fixed.
- All nodes have a fixed port order.
Remarks
- If fixed port sides are required, the PortPositionProcessor may be of use.
- Support for in-layer connections may be required to be able to handle certain problems. (odd port sides, for instance)
Current Implementations
- LayerSweepCrossingMinimizer. Does several sweeps across the layers, minimizing the crossings between each pair of layers using a barycenter heuristic. Supports node successor constraints and layout groups. Node successor constraints require one node to appear before another node. Layout groups specify sets of nodes whose nodes must not be interleaved.
Phase 4: Node Placement
So far, the coordinates of the nodes have not been touched. That's about to change in phase 4, which determines the y coordinate. While phase 3 has an impact on the number of edge crossings, phase 4 has an influence on the number of edge bends. Usually, some kind of heuristic is employed to yield a good y coordinate.
Our node placers may or may not support node margins. Node margins define the space occupied by ports, labels and such. The idea is to keep that space free from edges and other nodes.
Precondition
- The graph has a proper layering. (except for self-loops)
- Node orders are fixed.
- Port positions are fixed.
- An implementation may allow in-layer connections.
- An implementation may require node margins to be set.
Postcondition
- Each node is assigned a y coordinate such that no two nodes overlap.
- The height of each layer is set.
- The height of the graph is set to the maximal layer height.
Remarks
- Support for in-layer connections may be required to be able to handle certain problems. (odd port sides, for instance)
- If node margins are supported, the NodeMarginCalculator can compute them.
- Port positions can be fixed by using the PortPositionProcessor.
Current Implementations
- LinearSegmentsNodePlacer. Builds linear segments of nodes that should have the same y coordinate and tries to respect those linear segments. Linear segments are placed according to a barycenter heuristic.
Phase 5: Edge Routing
In the last phase, it's time to determine x coordinates for all nodes and route the edges. The routing may support very different kinds of features, such as support for odd port sides, (input ports that are on the node's right side) orthogonal edges, spline edges etc. Often times, the set of features supported by an edge router largely determines the intermediate processors used during the layout process.
Precondition
- The graph has a proper layering. (except for self-loops)
- Nodes are assigned y coordinates.
- Layer heights are correctly set.
- An implementation may allow in-layer connections.
Postcondition
- Nodes are assigned x coordinates.
- Layer widths are set.
- The graph's width is set.
- The bend points of all edges are set.
Remarks
None.
Current Implementations
- ComplexSplineRouter. TODO: Document.
- OrthogonalEdgeRouter. Routes edges orthogonally. Supports routing edges going into an eastern port around a node. Tries to minimize the width of the space between each pair of layers used for edge routing.
- PolylineEdgeRouter. TODO: Document.
- SimpleSplineEdgeRouter. TODO: Document.
Overview
Content Tools